Определение статистической значимости. Определение значимости воздействия
у меня нет ясности в понимании того, как определяется значимость ГОТОВЫХ контекстно-зависимых поведенческих цепочек. как я понимаю, поведенческая цепочна - это некоторая МОЗГОВАЯ активность. поведенческий контекст - это образ поведения при данном состоянии среды. состояние среды, отслеживается рецепторами органов чувств. чтобы определить значимость поведенческого контекста, надо получить предполагаемый результат поведения при данном состоянии среды, причем до того, как запустить поведенческую цепочку на выполнение. для этого к настоящему моменту в мозгу УЖЕ должен быть актевен образ вариантов поведений в некотором спектре состояний среды, содержащих отслеженное органами чувств в настоящий момент. так?
>>поведенческая цепочка - это некоторая МОЗГОВАЯ активность
Нет. Это последовательность звеньев, отвечающих за более элементарные действия в программе всей цепочки. По мере последовательной активности отдельных звеньев начинает выполняться вся программа отдельными подпрограммами.
>>поведенческий контекст - это образ поведения при данном состоянии среды
В одной цепочке в отдельных звеньях может быть ветвления на другие цепочки так, что при одних условиях активность продолжается по одной цепи, а в других условиях - по другим цепям. Это и есть контекст ность выполнения программы в зависимости от условий.
>>чтобы определить значим ость поведенческого контекст а, надо получить предполагаемый результат поведения при данном состоянии среды
С каждым звеном уже закреплена какая-то значим ость - как результат отработки данного звена цепи в определенных условиях. Эта значим ость может быть оценена только осознанным вниманием к данной цепочке. Без осознания значим ость играет разрешительную (положительная значим ость) или запретительную (отрицательная) роль. В случае, если в данных условиях со звеном ассоциирована отрицательная значим ость, то дальнейшая активность цепи прекращается.
Осознанное внимание может сканировать цепочку без выполнения действий (блокируя их) и получать значим ость, в том числе и окончательного звена, прогнозирующего результат действия.
Определение показателей значимости через градиент
Нейронная сеть двойственного функционирования может вычислять градиент функции оценки по входным сигналам и обучаемым параметрам сети.
Показателем значимости параметра при решении q- о примера будем называть величину, которая показывает насколько изменится значение функции оценки решения сетью q- о примера если текущее значение параметра w p заменить на выделенное значение w p . Точно эту величину можно определить произведя замену и вычислив оценку сети. Однако учитывая большое число параметров сети вычисление показателей значимости для всех параметров будет занимать много времени. Для ускорения процедуры оценки параметров значимости вместо точных значений используют различные оценки . Рассмотрим простейшую и наиболее используемую линейную оценку показателей значимости. Разложим функцию оценки в ряд Тейлора с точностью до членов первого порядка:
где H 0 q - значение функции оценки решения q- о примера при w =w. Таким образом показатель значимости p- о параметра при решении q- о примера определяется по следующей формуле:
Показатель значимости (1) может вычисляться для различных объектов. Наиболее часто его вычисляют для обучаемых параметров сети. Однако показатель значимости вида (1) применим и для сигналов. Как уже отмечалось в главе сеть при обратном функционировании всегда вычисляет два вектора градиента - градиент функции оценки по обучаемым параметрам сети и по всем сигналам сети. Если показатель значимости вычисляется для выявления наименее значимого нейрона, то следует вычислять показатель значимости выходного сигнала нейрона. Аналогично, в задаче определения наименее значимого входного сигнала нужно вычислять значимость этого сигнала, а не сумму значимостей весов связей, на которые этот сигнал подается.
Усреднение по обучающему множеству
Показатель значимости параметра X q p зависит от точки в пространстве параметров, в которой он вычислен и от примера из обучающего множества. Существует два принципиально разных подхода для получения показателя значимости параметра, не зависящего от примера. При первом подходе считается, что в обучающей выборке заключена полная информация о всех возможных примерах. В этом случае, под показателем значимости понимают величину, которая показывает насколько изменится значение функции оценки по обучающему множеству, если текущее значение параметра w p заменить на выделенное значение w p . Эта величина вычисляется по следующей формуле:
В рамках другого подхода обучающее множество рассматривают как случайную выборку в пространстве входных параметров. В этом случае показателем значимости по всему обучающему множеству будет служить результат некоторого усреднения по обучающей выборке.
Существует множество способов усреднения. Рассмотрим два из них. Если в результате усреднения показатель значимости должен давать среднюю значимость, то такой показатель вычисляется по следующей формуле:
Если в результате усреднения показатель значимости должен давать величину, которую не превосходят показатели значимости по отдельным примерам (значимость этого параметра по отдельному примеру не больше чем О§ p), то такой показатель вычисляется по следующей формуле:
Накопление показателей значимости
Все показатели значимости зависят от точки в пространстве параметров сети, в которой они вычислены, и могут сильно изменяться при переходе от одной точки к другой. Для показателей значимости, вычисленных с использованием градиента эта зависимость еще сильнее, поскольку при обучении по методу наискорейшего спуска (см. раздел ) в двух соседних точках пространства параметров, в которых вычислялся градиент, градиенты ортогональны. Для снятия зависимости от точки пространства используются показатели значимости, вычисленные в нескольких точках. Далее они усредняются по формулам аналогичным (3) и (4). Вопрос о выборе точек в пространстве параметров в которых вычислять показатели значимости обычно решается просто. В ходе нескольких шагов обучения по любому из градиентных методов при каждом вычислении градиента вычисляются и показатели значимости. Число шагов обучения, в ходе которых накапливаются показатели значимости, должно быть не слишком большим, поскольку при большом числе шагов обучения первые вычисленные показатели значимости теряют смысл, особенно при использовании усреднения по формуле (4).
Из анализа литературы и опыта работы группы НейроКомп можно сформулировать следующие задачи, решаемые с помощью контрастирования нейронных сетей.
1. Упрощение архитектуры нейронной сети.
2. Уменьшение числа входных сигналов.
3. Сведение параметров нейронной сети к небольшому набору выделенных значений.
4. Снижение требований к точности входных сигналов.
5. Получение явных знаний из данных.
Алгоритмы контрастирования, рассматриваемые в данной главе, позволяют выделить минимально необходимое множество входных сигналов. Использование минимального набора входных сигналов позволяет более экономично организовать работу нейркомпьютера. Однако у минимального множества есть свои недостатки. Поскольку множество минимально, то информация, несомая одним из сигналов, как правило не подкрепляется другими входными сигналами. Это приводит к тому, что при ошибке в одном входном сигнале сеть ошибается с большой степенью вероятности. При избыточном наборе входных сигналов этого как правило не происходит, поскольку информация каждого сигнала подкрепляется (дублируется) другими сигналами.
Таким образом возникает противоречие - использование исходного избыточного множества сигналов неэкономично, а использование минимального набора сигналов приводит к повышению риска ошибок. В этой ситуации правильным является компромиссное решение - необходимо найти такое минимальное множество, в котором вся информация дублируется. В данном разделе рассматриваются методы построения таких множеств, повышенной надежности. Кроме того, построение дублей второго рода позволяет установить какие из входных сигналов не имеют дублей в исходном множестве сигналов. Попадание такого «уникального» сигнала в минимальное множество является сигналом о том, что при использовании нейронной сети для решения данной задачи следует внимательно следить за правильностью значения этого сигнала.
Существует два типа процедуры контрастирования - контрастирование по значимости параметров и не ухудшающее контрастирование. В данном разделе описаны оба типа процедуры контрастирования.
В данном разделе описан способ определения показателей значимости параметров и сигналов. Далее будем говорить об определении значимости параметров. Показатели значимости сигналов сети определяются по тем же формулам с заменой параметров на сигналы.
Профессиональные аналитики уделяют много внимания статистической значимости, и это хорошо. Однако статистическая значимость - лишь один из аспектов хорошего анализа.
Проверка статистической значимости подразумевает выдвижение ряда предположений и определение вероятности того, что полученные результаты имели бы место в случае правильности выдвинутых предположений. Проверка статистической значимости поможет убедиться в том, что данные не вводят вас в заблуждение. Она с математической точки зрения покажет, достаточно ли значимо различие. Бывает, что различия, которые кажутся существенными, не являются таковыми, а бывает и так, что значимыми оказываются небольшие различия. Статистическая проверка позволит убедиться в правильности сделанных выводов.
На основе тестирования создана целая дисциплина. В деловом мире она известна как подход «тестируй и изучай» (test and learn ), включающий основные экспериментальные концепции, которые преподаются на курсах статистики. В среде «тестируй и изучай» эксперимент устроен так, что можно измерить эффекты использования одного или нескольких вариантов и определить, какой из них будет работать лучше всего.
Статистика давно уже стала неотъемлемой частью жизни. С ней люди сталкиваются всюду. На основе статистики делаются выводы о том, где и какие заболевания распространены, что более востребовано в конкретном регионе или среди определенного слоя населения. На основываются даже построения политических программ кандидатов в органы власти. Ими же пользуются и торговые сети при закупке товаров, а производители руководствуются этими данными в своих предложениях.
Статистика играет важную роль в жизни общества и влияет на каждого его отдельного члена даже в мелочах. Например, если по , большинство людей предпочитают темные цвета в одежде в конкретном городе или регионе, то найти яркий желтый плащ с цветочным принтом в местных торговых точках будет крайне затруднительно. Но из каких величин складываются эти данные, оказывающие такое влияние? К примеру, что представляет собой «статистическая значимость»? Что именно понимается под этим определением?
Что это?
Статистика как наука складывается из сочетания разных величин и понятий. Одним из них и является понятие «статистическая значимость». Так называется значение переменных величин, вероятность появления других показателей в которых ничтожно мала.
К примеру, 9 из 10 человек надевают на ноги резиновую обувь во время утренней прогулки за грибами в осенний лес после дождливой ночи. Вероятность того что в какой-то момент 8 из них обуются в парусиновые мокасины - ничтожно мала. Таким образом, в данном конкретном примере число 9 является величиной, которая и называется «статистическая значимость».
Соответственно, если развивать далее приведенный практический пример, обувные магазины закупают к концу летнего сезона резиновые сапожки в большом количестве, чем в другое время года. Так, величина статистического значения оказывает влияние на обычную жизнь.
Разумеется, в сложных подсчетах, допустим, при прогнозе распространения вирусов, учитывается большое число переменных. Но сама суть определения значимого показателя статистических данных - аналогична, вне зависимости от сложности подсчетов и количества непостоянных величин.
Как вычисляют?
Используются при вычислении значения показателя «статистическая значимость» уравнения. То есть можно утверждать, что в этом случае все решает математика. Самым простым вариантом вычисления является цепь математических действий, в которой участвуют следующие параметры:
- два типа результатов, полученных при опросах или изучении объективных данных, к примеру, сумм на которые совершаются покупки, обозначаемые а и b;
- показатель для обеих групп - n;
- значение доли объединенной выборки - p;
- понятие «стандартная ошибка» - SE.
Следующим этапом определяется общий тестовый показатель - t, его значение сравнивается с числом 1,96. 1,96 - это усредненное значение, передающее диапазон в 95 %, согласно функции t-распределения Стьюдента.
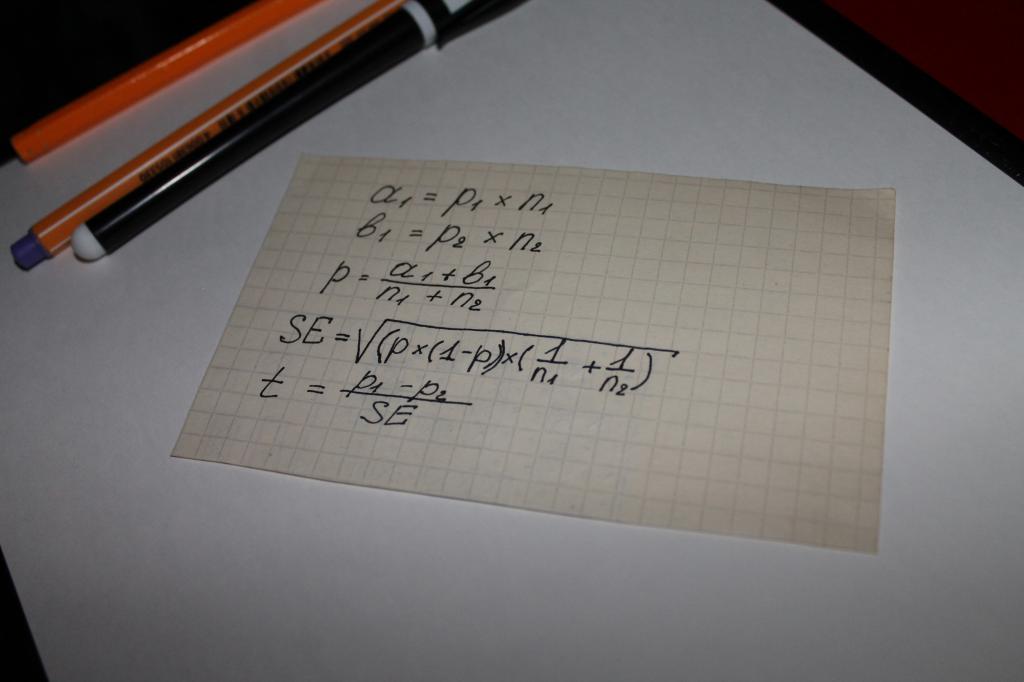
Часто возникает вопрос о том, в чем отличие значений n и p. Этот нюанс просто прояснить при помощи примера. Допустим, вычисляется статистическая значимость лояльности к какому-либо товару или бренду мужчин и женщин.
В этом случае за буквенными обозначениями будет стоять следующее:
- n - число опрошенных;
- p - число довольных продуктом.
Численность опрошенных женщин в этом случае будет обозначено, как n1. Соответственно, мужчин - n2. То же значение будут иметь цифры «1» и «2» у символа p.
Сравнение тестового показателя с усредненными значениями расчетных таблиц Стьюдента и становится тем, что называется «статистическая значимость».
Что понимается под проверкой?
Результаты любого математического вычисления всегда можно проверить, этому учат детей еще в начальных классах. Логично предположить, что раз статистические показатели определяются при помощи цепи вычислений, то и проверяются.
Однако проверка статистической значимости - не только математика. Статистика имеет дело с большим количеством переменных величин и различных вероятностей, далеко не всегда поддающихся расчету. То есть если вернутся к приведенному в начале статьи примеру с резиновой обувью, то логичное построение статистических данных, на которые станут опираться закупщики товаров для магазинов, может быть нарушено сухой и жаркой погодой, которая не типична для осени. В результате этого явления число людей, приобретающих резиновые сапоги, снизится, а торговые точки потерпят убытки. Предусмотреть погодную аномалию математическая формула, разумеется, не в состоянии. Этот момент называется - «ошибка».

Вот как раз вероятность таких ошибок и учитывает проверка уровня вычисленной значимости. В ней учитываются как вычисленные показатели, так и принятые уровни значимости, а также величины, условно называемые гипотезами.
Что такое уровень значимости?
Понятие «уровень» входит в основные критерии статистической значимости. Используется оно в прикладной и практической статистике. Это своего рода величина, учитывающая вероятность возможных отклонений или ошибок.
Уровень основывается на выявлении различий в готовых выборках, позволяет установить их существенность либо же, наоборот, случайность. У этого понятия есть не только цифровые значения, но и их своеобразные расшифровки. Они объясняют то, как нужно понимать значение, а сам уровень определяется сравнением результата с усредненным индексом, это и выявляет степень достоверности различий.

Таким образом, можно представить понятие уровня просто - это показатель допустимой, вероятной погрешности или же ошибки в сделанных из полученных статистических данных выводах.
Какие уровни значимости используются?
Статистическая значимость коэффициентов вероятности допущенной ошибки на практике отталкивается от трех базовых уровней.
Первым уровнем считается порог, при котором значение равно 5 %. То есть вероятность погрешности не превышает уровня значимости в 5 %. Это означает, что уверенность в безупречности и безошибочности выводов, сделанных на основе данных статистических исследований, составляет 95 %.
Вторым уровнем является порог в 1 %. Соответственно, эта цифра означает, что руководствоваться полученными при статистических расчетах данными можно с уверенностью в 99 %.
Третий уровень - 0,1 %. При таком значении вероятность наличия ошибки равна доле процента, то есть погрешности практически исключаются.
Что такое гипотеза в статистике?
Ошибки как понятие разделяются по двум направлениям, касающимся принятия или же отклонения нулевой гипотезы. Гипотеза - это понятие, за которым скрывается, согласно определению, набор иных данных или же утверждений. То есть описание вероятностного распределения чего-либо, относящегося к предмету статистического учета.

Гипотез при простых расчетах бывает две - нулевая и альтернативная. Разница между ними в том, что нулевая гипотеза берет за основу представление об отсутствии принципиальных отличий между участвующими в определении статистической значимости выборками, а альтернативная ей полностью противоположна. То есть альтернативная гипотеза основана на наличии весомой разницы в данных выборок.
Какими бывают ошибки?
Ошибки как понятие в статистике находятся в прямой зависимости от принятия за истинную той или иной гипотезы. Их можно разделить на два направления или же типа:
- первый тип обусловлен принятием нулевой гипотезы, оказавшейся неверной;
- второй - вызван следованием альтернативной.

Первый тип ошибок называется ложноположительным и встречается достаточно часто во всех сферах, где используются статистические данные. Соответственно, ошибка второго типа называется ложноотрицательной.
Для чего нужна регрессия в статистике?
Статистическая значимость регрессии в том, что с ее помощью можно установить, насколько соответствует реальности вычисленная на основе данных модель различных зависимостей; позволяет выявить достаточность или же нехватку факторов для учета и выводов.
Определяется регрессивное значение с помощью сравнения результатов с перечисленными в таблицах Фишера данными. Или же при помощи дисперсионного анализа. Важное значение показатели регрессии имеют при сложных статистических исследованиях и расчетах, в которых участвует большое количество переменных величин, случайных данных и вероятных изменений.
В конце нашего сотрудничества мы с Гэри Кляйном все же пришли к согласию, отвечая на основной поставленный вопрос: в каких случаях стоит доверять интуиции эксперта? У нас сложилось мнение, что отличить значимые интуитивные заявления от пустопорожних все же возможно. Это можно сравнить с анализом подлинности предмета искусства (для точного результата лучше начинать его не с осмотра объекта, а с изучения прилагающихся документов). При относительной неизменности контекста и возможности выявить его закономер ности ассоциативный механизм распознает ситуацию и быстро вырабатывает точный прогноз (решение). Если эти условия удовлетворяются, интуиции эксперта можно доверять.
К сожалению, ассоциативная память также порождает субъективно веские, но ложные интуиции. Всякий, кто следил за развитием юного шахматного таланта, знает, что умения приобретаются не сразу и что некоторые ошибки на этом пути делаются при полной уверенности в своей правоте. Оценивая интуицию эксперта, всегда следует проверить, было ли у него достаточно шансов изучить сигналы среды – даже при неизменном контексте.
При менее устойчивом, малодостоверном контексте активируется эвристика суждения. Система 1 может давать скорые ответы на трудные вопросы, подменяя понятия и обеспечивая когерентность там, где ее не должно быть. В результате мы получаем ответ на вопрос, которого не задавали, зато быстрый и достаточно правдоподобный, а потому способный проскочить снисходительный и ленивый ко нтроль Системы 2. Допустим, вы хотите спрогнозировать коммерческий успех компании и считаете, что оцениваете именно это, тогда как на самом деле ваша оценка складывается под впечатлением от энергичности и компетентности руководства фирмы. Подмена происходит автоматически – вы даже не понимаете, откуда берутся суждения, которые принимает и подтверждает ваша Система 2. Если в уме рождается единственное суждение, его бывает невозможно субъективно отличить от значимого суждения, сделанного с профессиональной уверенностью. Вот почему субъективную убежденность нельзя считать показателем точности прогноза: с такой же убежденностью высказываются суждения-ответы на другие вопросы.
Должно быть, вы удивитесь: как же мы с Гэри Кляйном сразу не додумались оценивать экспертную интуицию в зависимости от постоянства среды и опыта обучения эксперта, не оглядываясь на его веру в свои слова? Почему сразу не нашли ответ? Это было бы дельное замечание, ведь решение с самого начала мая чило перед нами. Мы заранее знали, что значимые интуитивные предчувствия командиров пожарных бригад и медицинских сестер отличны от значимых предчувствий биржевых аналитиков и специалистов, чью работу изучал Мил.
Теперь уже трудно воссоздать то, чему мы посвятили годы труда и долгие часы дискуссий, бесконечные обмены черновиками и сотни электронных писем. Несколько раз каждый из нас был готов все бросить. Однако, как всегда случается с успешными проектами, стоило нам понять основной вывод, и он стал казаться очевидным изначально.
Как следует из названия нашей статьи, мы с Кляйном спорили реже, чем ожидали, и почти по всем важным пунктам приняли совместные решения. Тем не менее мы также выяснили, что наши ранние разногласия носили не только интеллектуальный характер. У нас были разные чувства, вкусы и взгляды применительно к одним и тем же вещам, и с годами они на удивление мало изменились. Это наглядно проявляется в том, что каждому из нас ка жется занятным и интересным. Кляйн до сих пор морщится при слове «искажение» и радуется, узнав, что некий алгоритм или формальная методика выдают бредовый результат. Я же склонен видеть в редких ошибках алгоритмов шанс их усовершенствовать. Опять-таки я радуюсь, когда так называемый эксперт изрекает прогнозы в контексте с нулевой достоверностью и получает заслуженную взбучку. Впрочем, для нас в конечном итоге стало важнее интеллектуальное согласие, а не эмоции, нас разделяющие.





